TextAtlas5M is the first dense text image dataset.
🔥[2025-11-03] We update the arxiv version to include more models, including Qwen-Image, Grok3. We also include a pure-text evaluation benchmark, very easy to test with GITHUB. 🚀 Welcome to try it out! Reach our if you model is not included. 🚀
🔥[2025-02-19] We update the evaluation script of TextAtlasEval to evaluate model's ability on dense text generation. See GITHUB for more details. 🚀
🔥[2025-02-12] We introduce TextAtlas5M, a dataset specifically designed for training and evaluating multimodal generation models on dense-text image generation. 🚀
TextAtlas5M focus on generating dense-text images and stands out in several key ways compared to previous text-rich datasets. Unlike earlier datasets, which primarily focus on short and simple text, TextAtlas5M includes a diverse and complex range of data. It spans from interleaved documents and synthetic data to real-world images containing dense text, offering a more varied and challenging set of examples. Moreover, our dataset features longer text captions, which pose additional challenges for models, and includes human annotations for particularly difficult examples, ensuring a more thorough evaluation of model capabilities.

We design a dedicated test benchmark TextAtlasEval to address the longstanding gap in metrics for evaluating long-text information in image generation. By requiring models to effectively process and generate longer text, TextAtlas5M sets itself apart from existing text rendering benchmarks.
We thoroughly evaluate proprietary and open-source models to assess their long-text generation capabilities. The results reveal the significant challenges posed by TextAtlas5M and provide valuable insights into the limitations of current models, offering key directions for advancing text-rich image generation in future research.


The synthetic subset progresses through three levels of complexity, starting with simple text on clean backgrounds. It then advances to interleaved data, blending text with visual elements, and culminates in synthetic natural images, where realistic scenes integrate seamlessly with text.
The real image subset captures diverse, real-world dense text scenarios. It includes filtered samples from datasets like AnyText and TextDiffuser, detailed descriptions from PowerPoint slides, book covers, and academic PDF papers.
To enrich diversity, we also gather dense text images guided by predefined topics. To assess the capability of models in dense text image generation, we introduce a dedicated test set, TextAtlas5MEval, designed for comprehensive evaluation. This test set spans four distinct data types, ensuring diversity across domains and enhancing the relevance of TextAtlas5M for real-world applications.

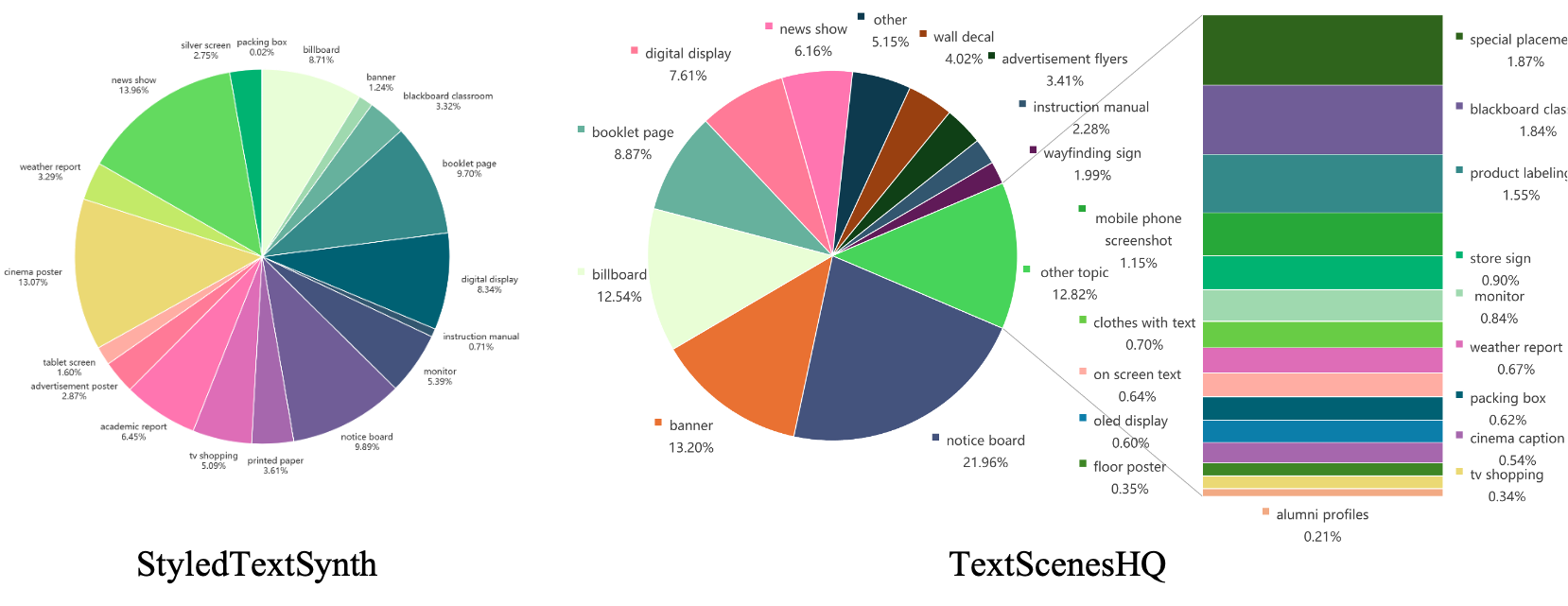
Topic distribution in StyledTextSynth and TextScenesHQ subset, showcasing a diverse range of text-rich topics such as weather reports, banners, and TV shopping ads. StyledTextSynth includes carefully selected 18 topics, while TextScenesHQ ultimately contains 26 distinct topics. These topics are generated using GPT-4 as a world simulator and then filtered by humans to eliminate overlap while ensuring diversity.
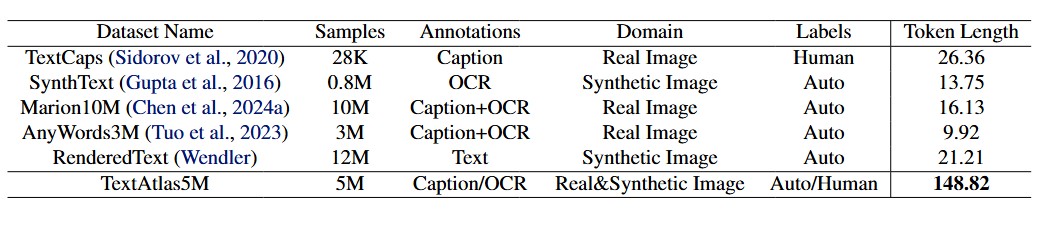
Dataset Comparison with Existing Text-Rich Image Generation Datasets. The last two columns detail the sources of automatically generated labels, while the final column presents the average text token length derived from OCR applied to the images.
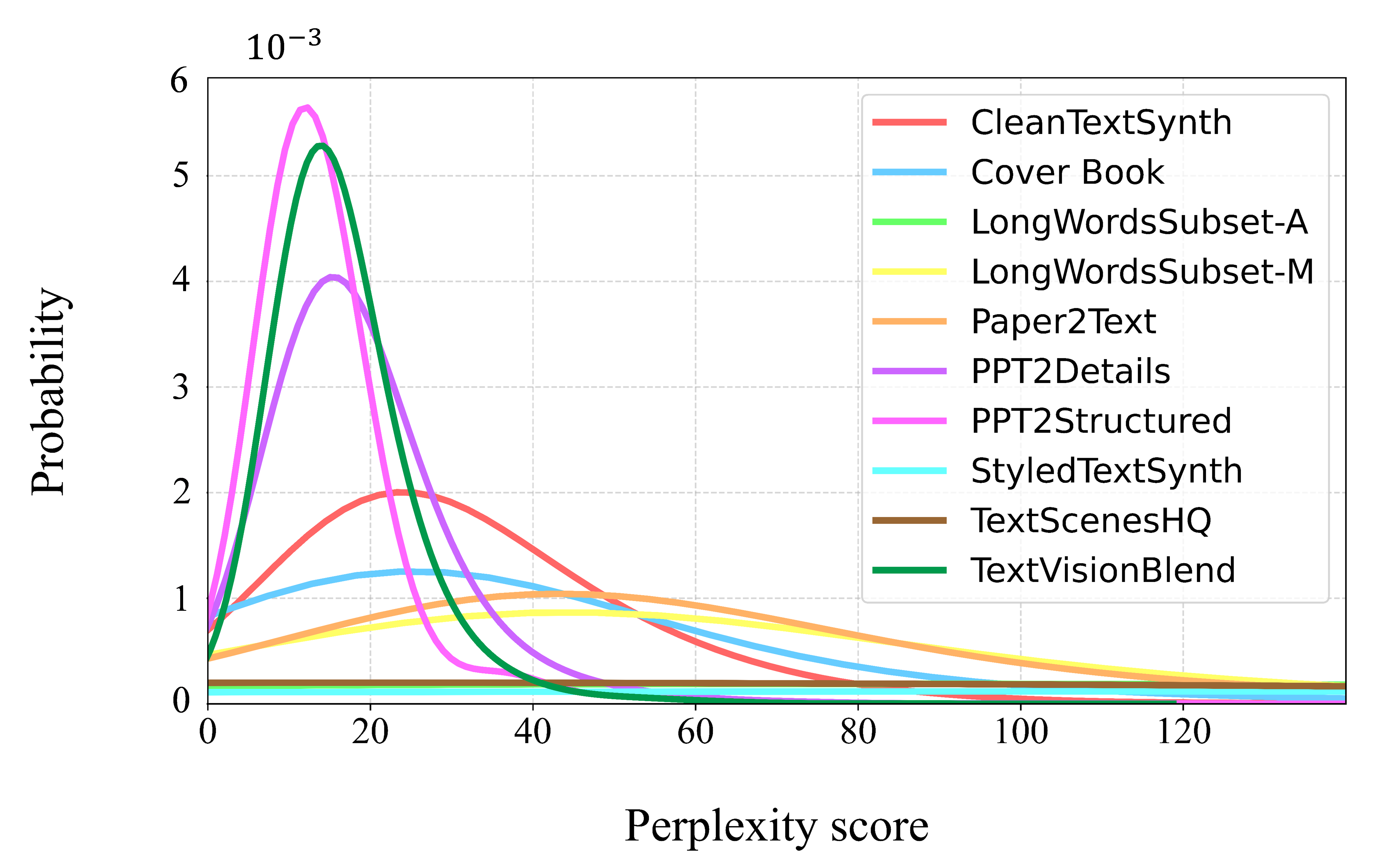
Kernel density estimations representing the distribution of perplexity scores for TextAtlas5M compared to reference datasets. The lower the perplexity for a document, the more it resembles a Wikipedia article.
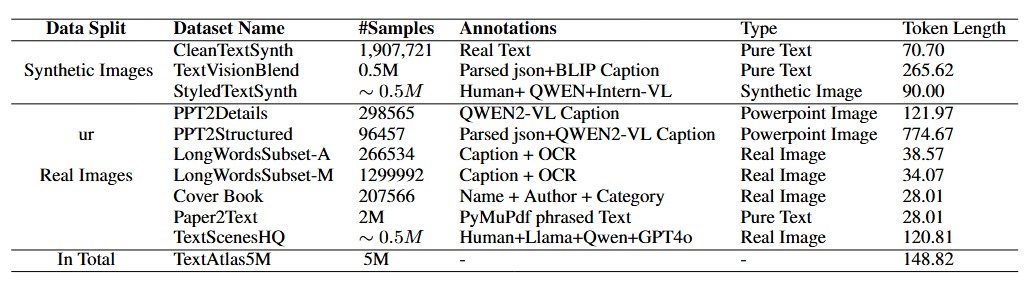
Data Level, Datasets, and Annotations Overview.
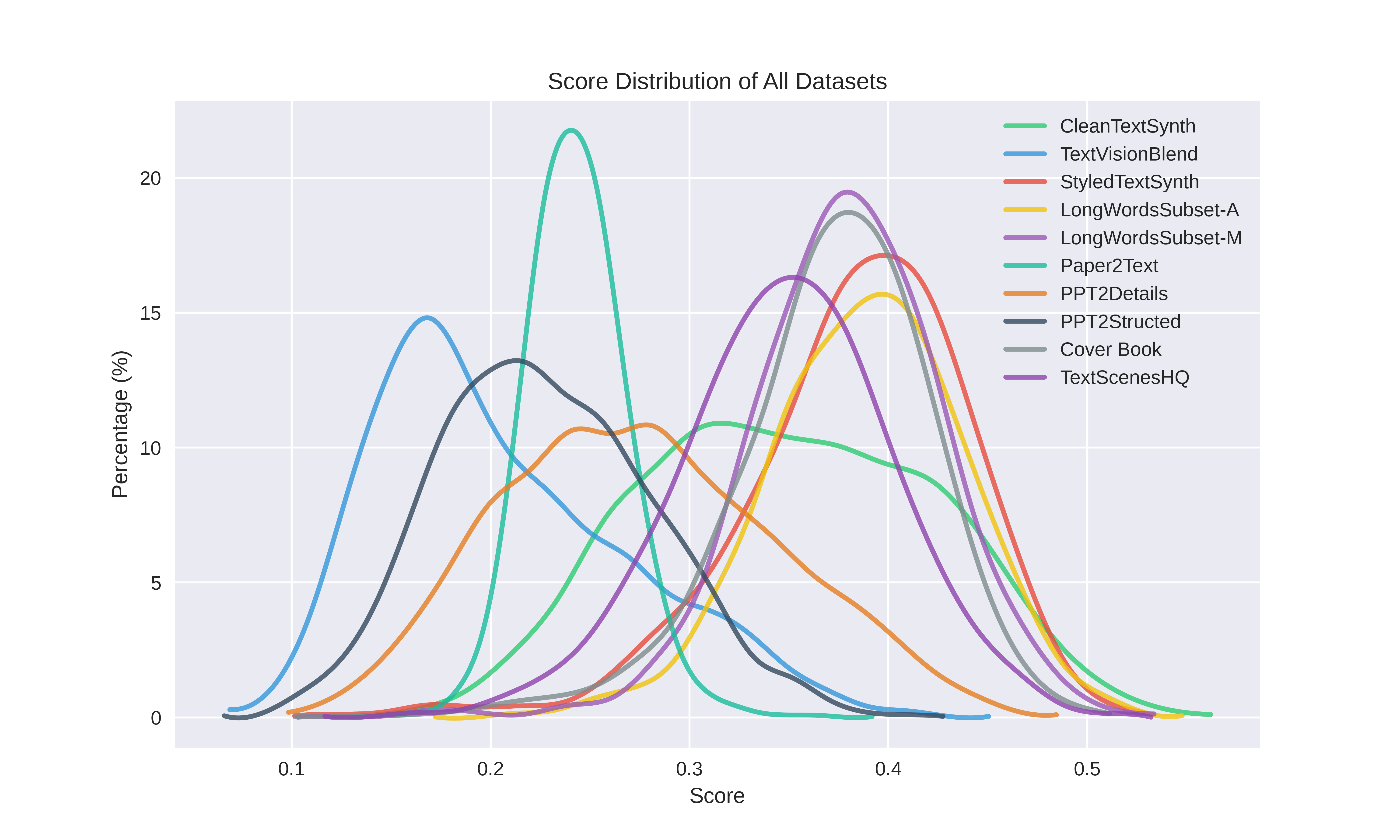
CLIP Score Distribution.
To evaluate the dense-text image generation ability for existing model, we further propose TextAtlas5MEval. Adopting stratified random sampling weighted by subset complexity levels: 33% from advanced synthetic tiers (Styled-TextSynth), 33% from real-world professional domains TextScenesHQ, and 33% from web-sourced interleaved TextVisionBlend coverage of both controlled and organic scenarios.
For the StyledTextSynth and TextScenesHQ subsets, we sample data from each topic to ensure the evaluation set covers a wide range of topics. For TextVisionBlend we perform random sampling to obtain the samples, and we finally get a test set with 3000 samples. In this way, our dataset cover different domain of data which allowing us to assess the capabilities of model across multiple dimensions.
Long text image generation evaluation over TextAtlas5MEval. Metrics include F1 score (F1), CLIP Score (CS), and Character Error Rate (CER).
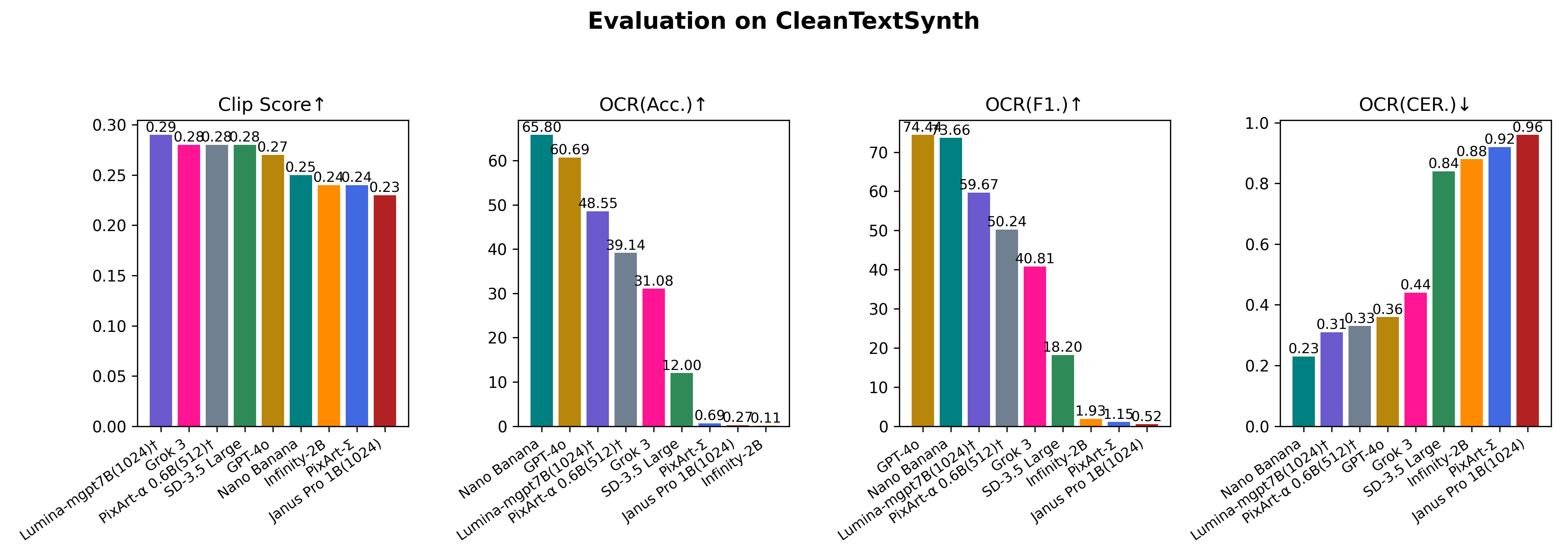
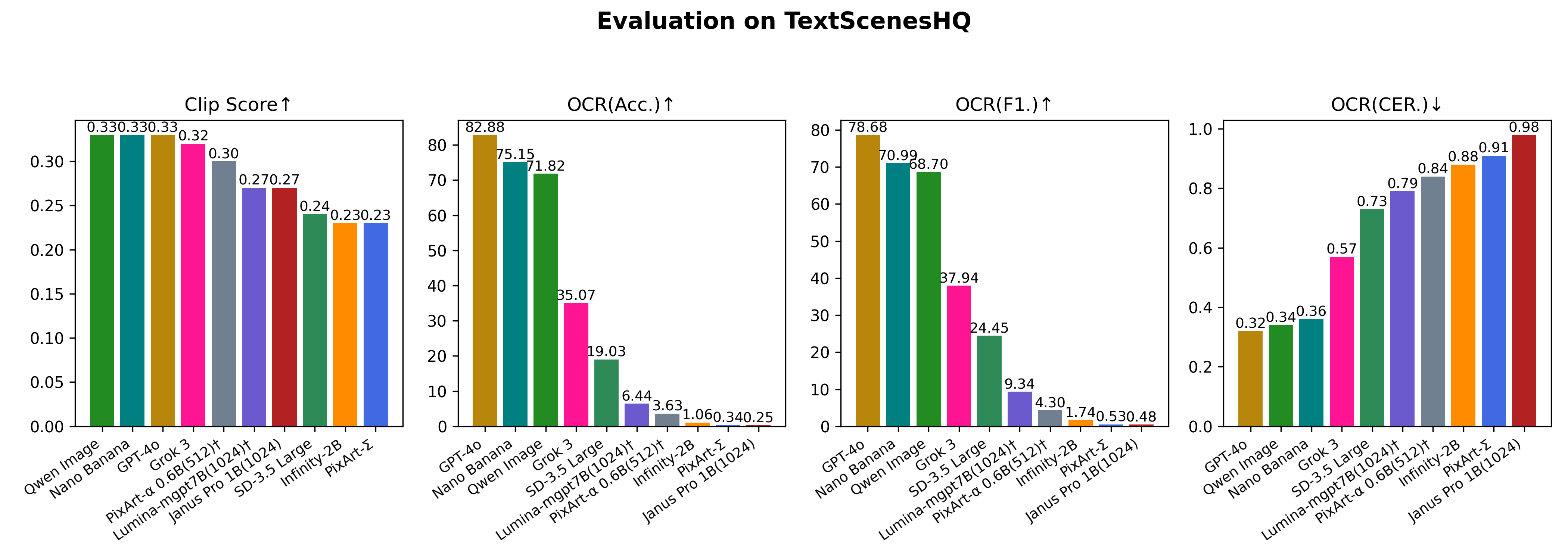
Evaluation On TextScenesHQ
| Method | Date | FID⬇ | CS⬆ | OCR(Acc.)⬆ | OCR(F1.)⬆ | OCR(Cer.)⬇ |
|---|---|---|---|---|---|---|
| GPT4o Image Generation | 2025-03-25 | - | 0.3330 | 82.88 | 78.68 | 0.32 |
| Qwen-Image | 2025-08-12 | - | 0.33 | 71.82 | 68.70 | 0.34 |
| DALL-E 3 | 2024-11-20 | 86.73 | 0.3367 | 69.26 | 51.63 | 0.67 |
| Grok3 | 2025-02-19 | - | 0.3197 | 35.07 | 37.94 | 0.57 |
| SD3.5 Large | 2024-06-25 | 64.44 | 0.2363 | 19.03 | 24.45 | 0.73 |
| Infinity-2B | 2024-12-05 | 71.59 | 0.2346 | 1.06 | 1.74 | 0.88 |
| PixArt-Sigma | 2024-03-27 | 72.62 | 0.2347 | 0.34 | 0.53 | 0.91 |
| TextDiffuser2 | 2023-11-16 | 84.10 | 0.2252 | 0.66 | 1.25 | 0.96 |
| Anytext | 2023-11-03 | 101.32 | 0.2174 | 0.42 | 0.80 | 0.95 |

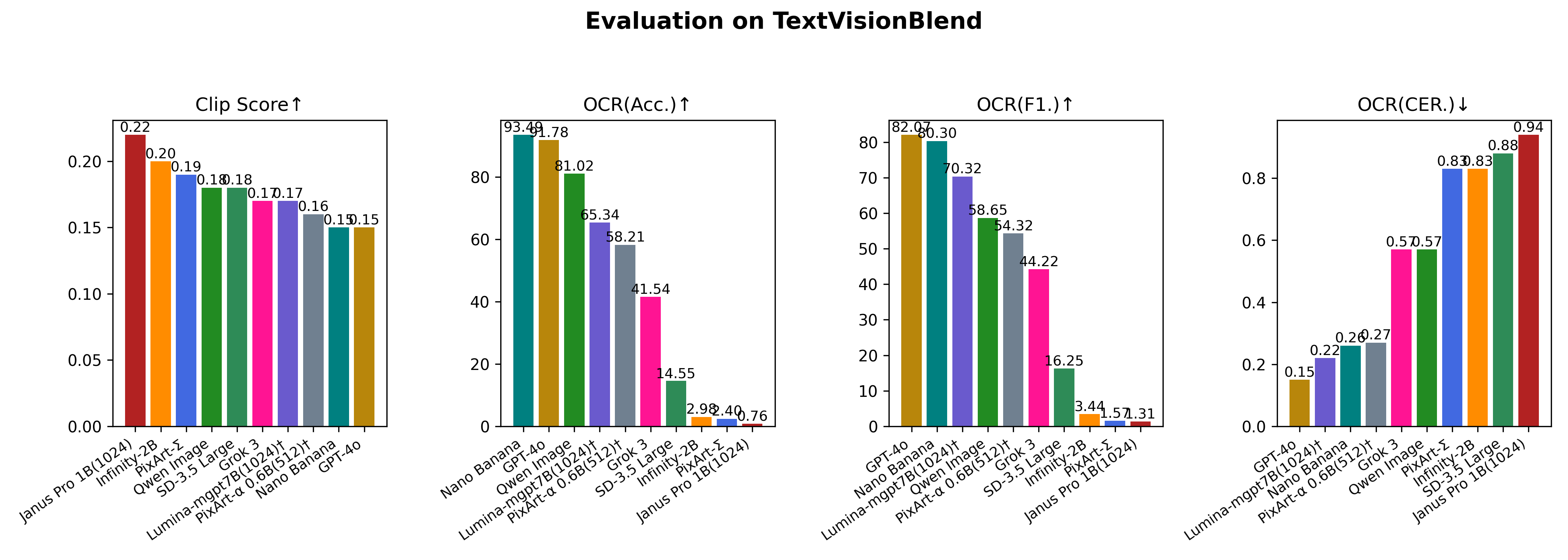
Evaluation On TextVisionBlend
| Method | Date | FID⬇ | CS⬆ | OCR(Acc.)⬆ | OCR(F1.)⬆ | OCR(Cer.)⬇ |
|---|---|---|---|---|---|---|
| GPT4o Image Generation | 2025-03-25 | - | 0.1490 | 91.78 | 82.07 | 0.26 |
| Qwen-Image | 2025-08-12 | - | 0.18 | 81.02 | 58.65 | 0.57 |
| Grok3 | 2025-02-19 | - | 0.1697 | 41.54 | 44.22 | 0.57 |
| SD3.5 Large | 2024-06-25 | 118.85 | 0.1846 | 14.55 | 16.25 | 0.88 |
| DALL-E 3 | 2024-11-20 | 153.21 | 0.1938 | 8.38 | 7.94 | 0.93 |
| PixArt-Sigma | 2024-03-27 | 81.29 | 0.1891 | 2.40 | 1.57 | 0.83 |
| Infinity-2B | 2024-12-05 | 95.69 | 0.1979 | 2.98 | 3.44 | 0.83 |

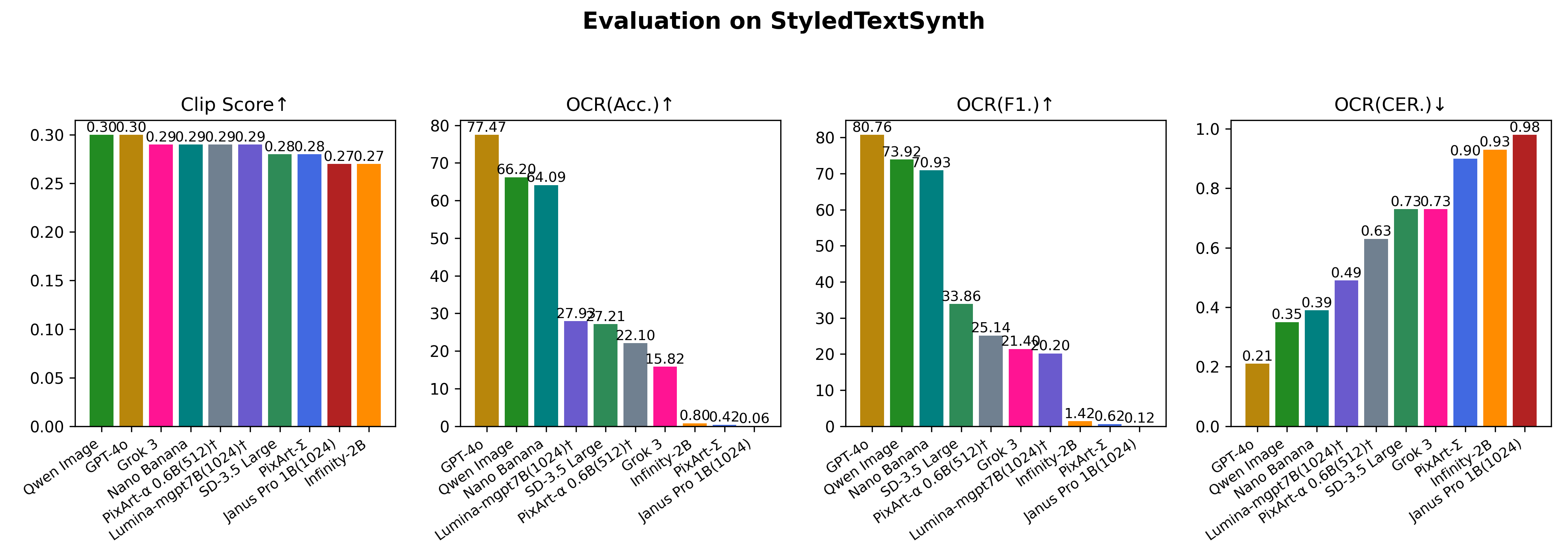
Evaluation On StyledTextSynth
| Method | Date | FID⬇ | CS⬆ | OCR(Acc.)⬆ | OCR(F1.)⬆ | OCR(Cer.)⬇ |
|---|---|---|---|---|---|---|
| GPT4o Image Generation | 2025-03-25 | - | 0.2968 | 77.47 | 80.76 | 0.21 |
| Qwen-Image | 2025-08-12 | - | 0.30 | 66.20 | 73.92 | 0.35 |
| SD3.5 Large | 2024-06-25 | 71.09 | 0.2849 | 27.21 | 33.86 | 0.73 |
| Grok3 | 2025-02-19 | 80.33 | 0.2854 | 15.82 | 21.40 | 0.73 |
| DallE3 | 2024-10-30 | 90.70 | 0.2938 | 30.58 | 38.25 | 0.78 |
| PixArt-Sigma | 2024-03-27 | 82.83 | 0.2764 | 0.42 | 0.62 | 0.90 |
| Infinity-2B | 2024-12-05 | 84.95 | 0.2727 | 0.80 | 1.42 | 0.93 |
| Anytext | 2023-11-03 | 117.71 | 0.2501 | 0.35 | 0.66 | 0.98 |
| TextDiffuser2 | 2023-11-16 | 114.31 | 0.2510 | 0.76 | 1.46 | 0.99 |


TextScenesHQ Examples_1

TextScenesHQ Examples_2

TextScenesHQ Examples_3

StyledTextSynth Examples_1

StyledTextSynth Examples_2

StyledTextSynth Examples_3


For any questions or suggestions, please contact us at m962479949@gmail.com. Or if you have any new models to evaluate, please contact us.
@article{wang2025textatlas5m,
title={TextAtlas5M: A Large-scale Dataset for Dense Text Image Generation},
author={Wang, Alex Jinpeng and Mao, Dongxing and Zhang, Jiawei and Han, Weiming and Dong, Zhuobai and Li, Linjie and Lin, Yiqi and Yang, Zhengyuan and Qin, Libo and Zhang, Fuwei and others},
journal={arXiv preprint arXiv:2502.07870},
year={2025}
}